
List, Series, DataFrameの違いを正確に理解する
最終更新日:2021/6/21
ここでは、これからコードを書く上で、絶対に知っておくべき事を説明します。ここが曖昧だと、思った結果が得られず、後で無駄な時間を割く事になります。最初に正確に理解することが重要です。
この3つの違いを理解・区別できないと、分析や機械学習に必要なデータは絶対に作れません。
List → Series → DataFrameの順で、出来る事が増えると考えればいいです。
DataFrameを作る(操作する)事が、データ分析、機械学習のための最初の目標です。これが出来れば、あとは何でもできます。
List, Series, DataFrameの3つの違い、その関係性を理解する事がとても重要です。
本サイトでは、コードを書く場合、List=li、Series=se、DataFrame=dfと書いて、出来るだけ明確に区別します。例えば、df1と書いたら、1番目の”DataFrame”という意味です。
【説明すること】
- 1. List(リスト : li)
- 2. Series(シリーズ : se)
- 3. DataFrame(データフレーム:df)
- どうやって使うのか?
- コラム:DataFrameとデータ・サイエンティストの関係
1. List(リスト : li)
Listはデータだけが入った箱です。例えば、数値データならば数値だけが入ります。Excelで、行も列も書かれていないシートに数字があるイメージです。
Excelで書くと、以下のように、行も列も書かれていないシートに数字があるイメージです。

2. Series(シリーズ : se)
SeriesはListに”index”という列が自動で振られたものです。データに、それを区別する背番号がついたものと考えればいいです。
Seriesは1次元のデータです。例えば、10人の身長と体重があった場合、10人を区別しますが、その身長しか入れられない箱(体重は入れられない)です。
もし、身長・体重の両方をセットで扱うと、これを2次元といい、1.3のDataFrameでしか扱えません。
indexというのは、背番号のようなもので、Pythonにより自動で振られます。この番号は「0」で始まり「0,1,2…」と続きます(「1,2,3…」でない)。
indexがあること自体も後で重要となります。
Seriesはpandasというライブラリーを使います。これは、最初にimport pandas as pd と書けばいいです。”as pd”の”pd”は好きな名前でいいのですが(例えば、自分の名前)、通常”pd”という”pandas”の略称を用います。”as pd”と書くことで、コードの中で”padas”と書くべきところが、”pd”と書くだけで済み、楽になります。
以下のようにpd.Series()と書きます。
左の0,1,2がindex。値として[1,2,3]を渡しましたが、indexは0始まりなので、index=0は1, index=1は2, index=2は3となっている事がわかります。
Excelで書くと以下のイメージです。青がindex。
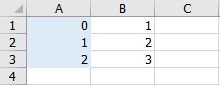
- 最初に
import pandas as pdと書く se1 = pd.Series()と書く (※se1はaでもなんでもいい)- Seriesは0始まりのindex(0,1,2…)が振られる
3. DataFrame(データフレーム:df)
DataFrameとは?
DataFrame(データフレーム)は、Seriesを何個もつなぎ合わせたもので、2次元以上のデータを扱う場合に用いるデータを入れる行と列を持ったハコです。例えば、身長と体重は、全ての人が持つ2つのデータであり、これを2次元のデータといいます。
DataFrameはExcelに相当するものであり、ExcelをPyhonが理解できるように書式を変えたものがDataFrameとも言えます。
ExcelとDataFrameの最も大きな違いは、DataFrameは視覚的に(マウスで)編集する事が出来ない点です。コードを書いて操作するしかありません。
DataFrameはindex(行番号)とカラム名(列名, column name)を持っています。
indexがExcelの行番号に相当し、カラム名がExcelの列名に相当します。
index、カラム名はSeriesと同様にPythonが自動で番号を振りますが、実践ではユーザーが指定する事が多いです。また、index、カラム名もやはり0始まりで「0, 1, 2, …」と振られます。
ざっくり言うと、PyhonはDataFrameをデータと認識して処理を行うので、DataFrameが分からなければ、Pythonでは何も出来ません。逆に言うと、DataFrameを完璧に理解して、自由に操れれば、Pythonの学習は半分以上終わったと言ってもいいのです。
どうやって使うのか?
Series同様にpandasというライブラリーを使います。これは、はじめにimport pandas as pdと書き、以下のようにpd.DataFrame()と書きます。この例ではListからDataFrameを作成しています。[11,12,13]がListです。
後述しますが、何からDataFrameを作るのか、を常に意識する事がとても重要です。例えば、List以外に、SeriesからDataFrameを作ることも考えられます。
左の列0, 1, 2がindexで、上の番号0がカラム名です。このように0始まりです。DataFrameの値を[11, 12, 13]と渡しましたが、Pyhonは0行0列目=11, 0行1列目=12, 0行2列目=13と0始まりで認識します。
index名、カラム名を指定する場合には以下のように書きます。index名がA, B, Cで、カラム名がclm1とした場合です。実践ではカラム名(columns=の部分)を指定する事がとても多いです。
Excelで書くとそれぞれ以下のイメージです。青がindex、緑がカラム名。

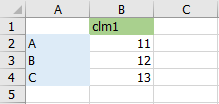
- 最初に
import pandas as pdと書く df1 = pd.DataFrame()と書く (※df1はaでもなんでもいい)- DataFrameは0始まりのindex(0,1,2…)とカラム名が振られる
- indexとカラム名は自由に変えられる
コラム:DataFrameとデータ・サイエンティストの関係
データサイエンスでは、このDataFrameが頻繁に用いられます。
データサイエンス、機械学習、AIでは、DataFrameを自在に操り必要なデータを作成する事が、最も重要な部分であり、この部分に全体の8割の時間を割くと言われます。(残り2割で分析を行う。)
DataFrameを自在に操り、欲しいデータを作成する事はとても難しいです。
ですが、DataFrameを自在に操れるのであれば、データ・サイエンティストの要件の大部分は満たされています。
それは、データが作れれば、結果は簡単に出てくるからです。何をデータにするか、結果をどう捉えるか、は高度な数学が必要で、ここに個人の能力が強く反映されます。
しかながら、少なくとも「データを作成する」までは、殆どの人が努力で達成する事が出来ますし、今後、Excelと同様に必須のスキルになるでしょう。