
ありがちなExcelファイルを読み込む
最終更新日:2022/2/7
Excelファイルを読み込む方法を説明します。
pandasのread_excel()を使うのですが、2つ重要な点があります。
- ライブラリーのインストール
openpyxlとxlrdというライブラリーを予めインストールしてください。 - engine=””の指定
pandasのバージョンによっては、read_excel()は、pd.read_excel(engine=”openpyxl”)のようにengineを指定しないと動きません。この場合、読み込むファイルの種類(.xlsx, .xlsm, .xls)により変更する必要があります。
2022/2/7追記:
現在では、通常、.xlsx形式であれば、engineを指定する必要はありません。しかし、何度実行しても動かない場合は、engineを指定してください。pandasのバージョン変更時に、何度か仕様が変更され、お使いのバージョンによってはengineの指定が必要です。
APIドキュメントはこちら
https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html
【説明すること】
- 1. pandasでExcelファイルを読み込む
- 読み込みの基本:
pd.read_excel() - 読み込む範囲を指定する:
skiprows=, skipfooter=, usecols= - 列番番号で指定する :
usecols= - 列名で指定する :
usecols= - indexにする列を指定する:
index_col= - 【よくある困った】Excelにない範囲をPythonが拾っている!
- 読み込みの基本:
- 2. 全てのシートを連続的に読み込む
- openpyxlでExcelの情報を取得する:
opx.load_workbook() - 読み込んだデータを後で呼び出したい場合
- openpyxlでExcelの情報を取得する:
Excelも基本的にcsvと同様ですが、以下がポイントとなります。
pd.read_excel()を使うsheet_name=”シート名”で指定するengine=”openpyxl”(.xlsx,.xlsm)またはengine=”xlrd”(.xls)を指定する
【参考HP】
https://note.nkmk.me/python-pandas-read-excel/
1. pandasでExcelファイルを読み込む
Excelの読み込みは、pandasの pd.read_excel() を使います。pandasのバージョンによっては、オプションのengine=を、以下のように拡張子(.xlsxや.xls)に応じて指定する必要があるので、どのExcelファイルを読み込むのかを意識する事がとても重要です。
【eingine=””の指定】
- .xlsx, .xlsm :
engine=”openpyxl” - .xls :
engine=”xlrd”
※2022/2/7追記:
pandasのバージョン変更で仕様が何度か変更され、現在では、.xlsx形式であれば、engineを指定する必要はありません。
以下では、pandasの古いバージョンで問題に直面した場合でも解決できるように、engineを指定する前提で書いています。指定しなくても動く場合は気にする必要はありません。
但し、「engineというオプションがある」という事はとても重要な知識です。
読み込んだデータは基本DataFrameとなります。
ここでは、以下のようなExcelファイルを読み込みます。必要な部分は青で囲んだ部分です。それ以外は不要です。それを実現する為に、いくつかのオプションを指定します。
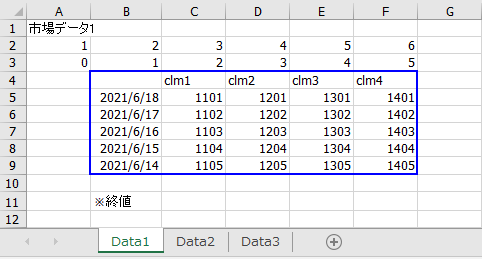
読み込みの基本
pandasでpd.read_excel(ファイル名, sheet_name=”シート名”, engine=”openpyxl”)(.xlsx,.xlsmの場合)
で読み込みます。
結果はdfで返されるので、それを受け取るdfを用意して以下のように書きます。df1a = pd.read_excel(p1f1, sheet_name='Data1', engine='openpyxl')
結果は次のようになります。データの範囲は、Pythonが自動で判別してくれます。
結果が”Unnamed: 0”となるのは、データがないものをヘッダーとして読み込んでいるからです。
ここで、NaNが多数含まれていますが、これは欠損値です。本来不要なものです。一方で、必要な範囲は(余計なものを含むにせよ)読み込まれているのがわかります。
Excelで「不要な範囲」は行が上の1~3行目、下の10,11行目、列がA列です。これらを除いて読み込む為に、いくつかのオプションを指定します。但し、列は「読み込みたい列を指定する」と考えます。
読み込む範囲を指定する
skiprows = : 上から数えて除外する行の数 (例. skiprows=3だと1,2,3行目。1始まり)skipfooter = : 下から数えて除外する行の数 (例. 2だと、1行目から2行目。1始まり)usecols= : 読み込む列の指定
usecols=について
ここで、usecols=について説明します。
列番号で指定する
usecols=range(1,6)とすると、Pythonの1~5列まで(6列は除く)で、「0始まり」で指定します。例えば、先頭から3列の場合はrange(0,3)と指定します。usecols=range(1,6)は、このExcelで見た場合、Excelの2~6列目です。usecols=[1,5]とすると、Pythonの1列目と5列目で、「0始まり」で指定します。このExcelで見た場合、Excelの2列目、6列目です。
列名で指定する
usecols=は列名でも指定可能です。usecols='B:F'と書くと、ExcelのB列~F列までとなります。usecols='B:C,F'と書くと、ExcelのB列からC列まで、とF列、となります。
ファイル内のindexにする列を指定する
indexにしたい列があればindex_col=に番号で指定します。ここで指定する番号は、範囲を指定して切り取った後の列番号です。例えば、以下のように usecol=range(1,6)とした場合、切り取ったPython上の1~5列の中での0列目という意味です。つまり、range(1,6)の「1」がindex_col=0の「0」に該当します。
【よくある困った】
Excelにない範囲をPythonが拾っている!
Excelシートにデータがないのに、Pythonで読み込んだ行、列がExcelよりも広い場合があります。これらは多くの場合NaN(欠損値)として表示されます。
これは、Excelに、見かけ上データはありませんが、実は何かが残っている場合です。
例えば、何かデータをいれて、それをDeleteボタンで消去して、上書き保存した場合が考えられます。
対処法は、元のExcelファイルを開き、意図せず読み込まれた行または列を、可能な限り多く選択し、「行の削除」または「列の削除」をして上書き保存します。
2. 全てのシートを連続的に読み込む
openpyxl でExcelの情報を取得する
同じ形式のシートであれば、一度にまとめてデータを読み込みたい場合があります。例えば、以下のようなExcelです。シートはData1, Data2, Data3の3つです。これをまとめて読み込む方法を説明します。
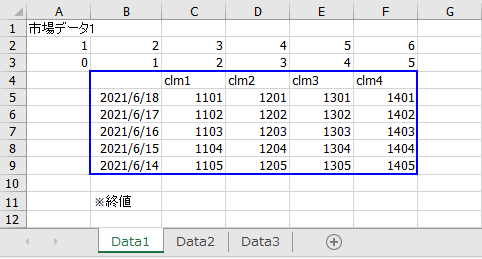
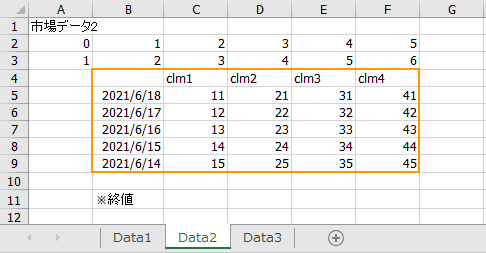
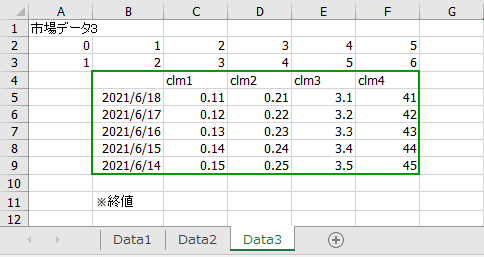
この場合、opepyxlというライブラリーと組み合わせて、以下のように書きます。
最初のimport openpyxl as opxは、openpyxlというライブラリーを読み込み、opxと名前を付けるという意味です。通常、opxと名前を付けます。
opx.load_workbook()にファイル名を指定します。例えば
opx.load_workbook(‘C:\Users\shilabo\Documents\SHiLABO_python\a001_003_data1.xlsx’)
です。コードでは変数を使っています。
wb =opx.load_workbook(p1f1)とwbを受け皿に書くと、そのExcelファイルの各種情報がwbに格納されます。wb.sheetnamesと書くことで、全てのシート名が得られます。シート名はlistで返されるので、listの受け皿を書きます。ここではli_shtとしています。
ここから、li_shtを使ったfor文で書いて、各シートを読み込みます。
ただし、このコードでは、その後で読み込んだdfが呼び出せません。
読み込んだデータを後で呼び出したい場合
後で、読み込んだデータを呼び出したい場合があります。この場合、例えば、以下のように、あたかも複数のdfをlistの要素のようにすれば可能です。
li1, li2, li3はダミーのlistと考えください。li_df3 = [li1, li2, li3]でダミーのlistを作成しておきます。読み込むシートの数と同じ数の要素がli_df3にないとエラーとなります。
上記で読み込んだdfを呼び出す場合、li_df3[0]のように、listの要素として呼び出す必要があります(li1と呼び出しても、空と返します)。
これは意外と不便なので、数が少ないならば、1つずつdfの名前を書く事が多いです。
【覚えたこと】
- Excelを読み込む: pd.read_excel()
- pandasの
pd.read_excel()を使う engine=”openpyxl”またはengine=”xlrd”を指定するskiprows=, skipfooter=, usecols=で範囲を指定するindex_col=でindexにする列を指定する- openpyxl(=opx)
wb=opx.load_workbook()で情報を読み込むwb.sheetnamesでシート名を取得