
実際にありがちなcsvファイルを読み込む
最終更新日:2022/1/21
DataFrameに入る前に、csvファイルの読み込みを説明します。
なぜならば、DataFrameは通常、与えられたデータをインポートして作成するので、ファイルの読み込みを習得した方が実践的だからです。
【説明すること】
- 1. pandasでcsvファイルを読み込む:
pd.read_csv() - 2. pandasで行、列の範囲を指定して csvを読み込む
- 2.1 日本語を含んだファイルの場合:
pd.read_csv(encoding="shift_jis") - 2.2 範囲を指定する:
pd.read_csv(skiprows=, skipfooter=, usecols=) - 3. 日付をindexとして読み込む:
pd.read_csv(parse_dates=True) - まとめ
読み込むファイルはcsv形式(.csv)が好んで用いられます。csvは書式がなく、扱いやすいのです。
Excel(.xlsx)を読み込む事も多いですが、まずはcsv形式を習得する事が重要です。
csvが読み込めれば、Excelもほぼ同じ手順でできます。
後で見るように、Pythonは日本語がひどく苦手です。インポートするデータは英語だけにしておくべきです。
データのインポートが出来ないと、何も出来ないに等しいです。
尚、当サイトではよく使う部分のみを説明し、詳細は他のHPに譲ることにします。
例えば、以下のサイトが非常に役に立ちます。極めて質の高い無料のサイトです。
https://note.nkmk.me/python-pandas-read-csv-tsv/
1. pandasでcsvファイルを読み込む
csvの読み込みは、pandasのpd.read_csv() を使います。
これを使う為に最初にimport pandas as pdと書きます。
読み込んだデータはDataFrameとなります。
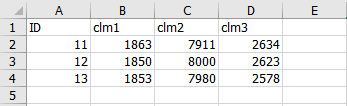
ここでは、以下のようなcsvファイルを読み込みます。
データはA列が行の名前、B~D列がカラム名(列名)です。
通常、このようにデータには、行の名前(11, 12, 13)と列名(clm1, clm2, clm3)が付いています。列名はヘッダー(header)と呼ばれます。
これを、行の名前が(11, 12, 13)となるように、読み込もうと思います。DataFrameとして読み込んだ、行の名前のことをindexといいます。
以下のリンク(GitHub:外部サイト)を右クリックして「名前を付けてリンク先を保存」か、一度開いてメモ帳にコピペして保存してください。その際に、拡張子が自動で「.txt」となりますが、「.csv」とタイプして保存してください。
例えば、ファイル名を直接「a001_001a.csv」とタイプしてください。
Pythonでは、 pd.read_csv('ファイルのパス') で読み込みます。
ファイルのパスは、例えば、Windowsのドキュメントに保存した場合、
C:\Users\ユーザ名\Documents
となります。以下はユーザー名が “shilabo” で、ドキュメントフォルダの中に “SHiLABO_python” というフォルダを作った場合です。
パスを指定する場合”r”を頭に書くと\を\\と書く必要がなくなり便利です。Windowsのエクスプローラーからパスをコピーして、そのままペーストするだけよくなります。
あるいは、パスとファイル名を分けた方がいい場合があります。例えば、ループ(for文)で同じパスの複数のファイルを読み込みたい場合です。
その為、実務では以下のように書くことがあります。
結果はどちらも同じです。
ただし、これでは目的が達成されていません。indexが自動で0,1,2と振られ、A列の11, 12, 13はデータとして扱われています。本来はA列の11, 12, 13をindexにしたかったはずです。
そこで、オプションのindex_col=0, header=0 を使います。デフォルトはheader=0なので、これは省略できます。
indexはカラム名(列名)で指定することもできます。以下は、’clm1’をindexにした場合です。
2. pandasで行、列の範囲を指定してcsvを読み込む
2.1 日本語を含んだファイルの場合
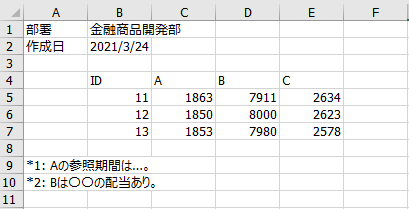
しかし、現実には、このように元がきれいなデータである事は少なく、多くの場合、以下のように、余計なものが含まれています。しかも、日本語の嵐。Pythonは日本語が苦手です。
欲しいのは、セル「B4:E7」の範囲だけです。
これもpandasのpd.read_csv()で読み込みますが、日本語を含む場合、オプションにencoding='shift_jis' を指定します。
“shift”と”jis”の間はアンダースコア(_)であり、ハイフン(-)ではありません。
これを間違い、データが読めないと悩む人が多いです。因みに、他に英語を読み取るencoding = 'utf-8'がありますが、こちらはハイフン(-)です。
とりあずencoding='shift_jis'を指定して実行すると、以下のようになります。
読み込めていますが、csv上で空白も読み込み(NaN)、不必要なデータ(日本語部分)も読み込んでいます。これは意図とは異なります。データだけが必要なのです。むしろ、データ以外は取り込んではいけない、と言った方がいいでしょう。
2.2 範囲を指定する
そこで範囲を指定する為に、以下のオプションを指定します。
skiprows=3 : 最初の3行はスキップ(1~3行目)skipfooter=3 : 下から3行はスキップ(8~10行目)usecols=range(1,5) : 列の指定(Python上での1列~4列目 = csv上では2列目(B列)から5列目(F列))
skipfooter=でWarningが出た場合、更にオプションで engine='python'を指定します。
ここで、usecols=について説明します。
range(1,5)と書くと、0始まりのPythonから見て、1, 2, 3, 4列目となります。
つまり0列目はスキップし、1, 2, 3, 4列目を読み、5列目は含みません。
csv上では普通1, 2, 3…列と数えるし、終わりの5も含むか含まないか、この感覚が難しいです。
実際には、print()で意図通りか必ず確認します。
また、index_col=0はusecols で切り取った後の、Pythonの0列目をindexにする、という意味です。
同様に、header=0は、skiprowsで切り取った後の、Pythonの0行目をヘッダーにする、という意味です。
Pythonは基本0で始まります(1ではない)。
usecols の範囲はリストで指定することもできます。
この例の場合、usecols=[1,2,3,4]。ここでも、0始まりを意識しましょう。
3. 日付をindexとして読み込む
日付がある時系列データを読み込む場合、”型”をdatetime型として読み込むと便利です。
index_col=でindexとするカラム名(列名)を指定し、parse_dates=Trueのオプションを指定します。
以下のcsvファイルを読み込んでみます。
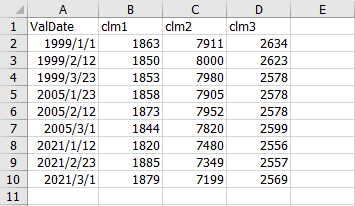
indexをdatetime型にすると、df.index.year == , df.index.month == , df.index.day ==と書くことで、年、月、日でフィルターをかけることができます。
以下は、1999年だけ、2月だけ、23日だけ、の例です。
年、年月の指定ならば、以下のようにdf.loc['1999']やdf.loc['2021-02']でも可能です。
注意:df['1999']やdf['2021-02']でも可能でしたが、以下のワーニングが出るようになりました。この意味は、「今後はこの形式では使用できなるので、かわりに.loc[]を使って、df.loc['1999']の形式を使用しろ」ということです。(2022/1/21追記)
108: FutureWarning: Indexing a DataFrame with a datetimelike index using a single string to slice the rows, like frame[string], is deprecated and will be removed in a future version. Use frame.loc[string] instead.
indexをdatetime型にした場合の使い方は、次のサイトが詳しいです。
https://qiita.com/sakabe/items/ae1fa47a58c796006627
まとめ
pd.read_csv()にいくつもオプションを指定すれば、不要なものを含むcsvファイルもデータとして読み込めます。しかし、とても面倒です。
現実には難しいですが、出来れば、読み込むcsvファイルの不要部分を削除し、シンプルなデータ形式にしておくのがいいです。その方が時間が省略できます。
また、日本語が含まれると、エラーの原因になり、その解決に時間が掛かるので、可能ならば日本語は避けた方がいいです。
pd.read_csv()を使う。- 日本語を含む場合、
encoding='shift_jis'をオプションに指定する。 skiprows=, skipfooter=で上下の範囲(行)を指定できる。skipfooter=でエラーが出たらengine='python'を指定する。usecols=で左右(列)の範囲を指定できる。index_col=でindexにする列を指定できる。- indexをdatetime型で読み込む場合、
parse_dates=Trueを指定する。